音视频基础介绍
本篇重点
音视频基础概念与相关术语的讲解
什么是视频
图像的组成
在说视频之前,我们来聊一下图像,图像是人对视觉感知的物质再现。图像是使用像素点阵来表示的,每个像素点都分配有特定的颜色和位置值。像素也是图像显示的基本单位,通常一幅1080x1920的图片,就是长度1920个像素点,宽度1080个像素点组成的矩阵。
颜色空间
像素点除了有位置外还需要有颜色信息,那么颜色在计算机中是如何表示呢?
在计算机中颜色空间有很多,这里我们介绍下常用的两种颜色空间,RGB颜色空间和YUV颜色空间。
RGB颜色空间
RGB颜色空间是由红绿蓝三原色来定义,通过三原色混合成所有的颜色,这应该是我们最熟悉的一种颜色空间。
YUV颜色空间
Y表示亮度,U和V表示色度和浓度。早期的YUV实际上是用在彩色电视和黑白电视的交替上,感兴趣历史的同学可以点击YUV查看相关资料。YUV颜色空间在数字媒体中广泛使用是由于人类对亮度的的敏感度高于对色度的敏感度,但是在数字媒体中使用的是个变体,叫YCbCr,其中Cb是指蓝色色度,Cr就是红色色度。像JPEG、MPEG都是采用此格式,后续一般讲的YUV都是指YCbCr。(Y的值是根据RGB值计算出来的,所以Cg的值可以通过CbCr计算出来,所以在传输的时候只需要传输YCbCr)
1 | 计算公式: |
YCbCr会按照一定的采样比对色度数据进行采样,采样比通常表示为 __J : a : b__,表示在一个宽为J像素、高为2像素的采样区域中进行采样,J表示采样的宽度,通常是4,a表示第一行色度采样数,b表示第二行色度采样数与第一行色度采样的不同样点数。
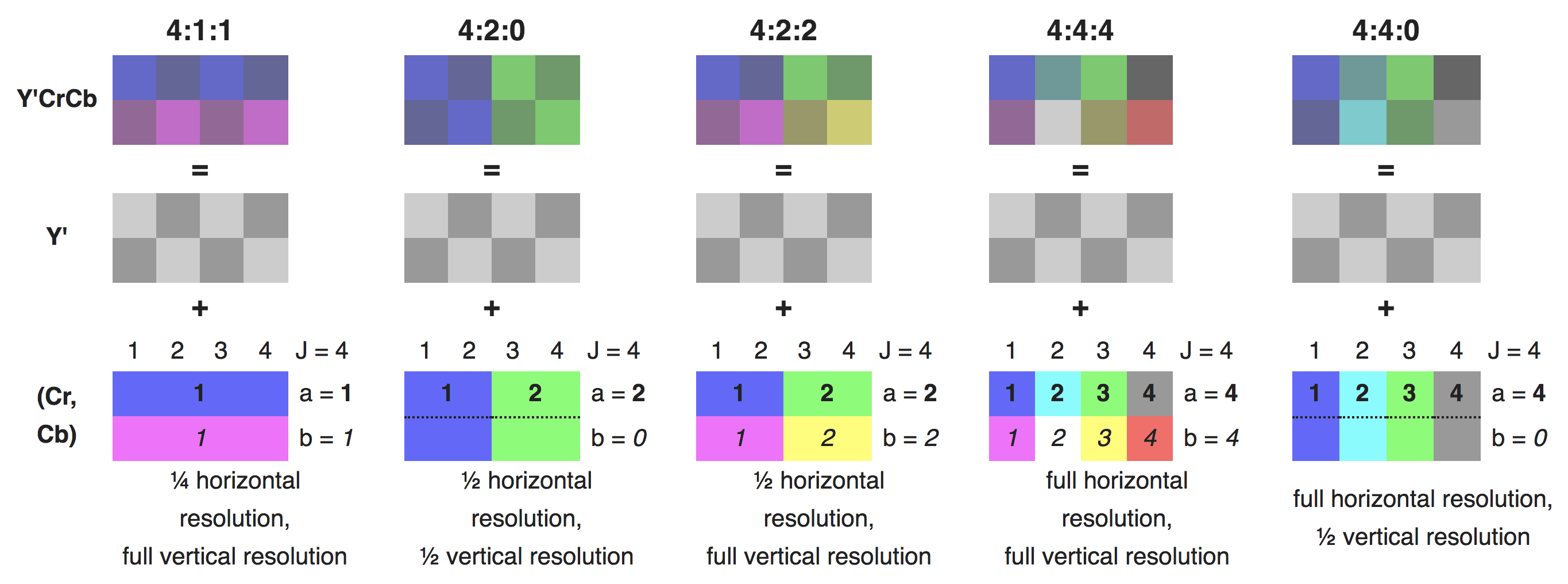
最常见的采样比是 4:2:0 ,表示宽为4,第一行有两个色度采样点,第二行与第一行完全相同。所以总共有八个亮度采样点和两个色度采样点,每个亮度采样点需要记录一个值Y,而每个色度采样点都需要记录两个值Cb和Cr。最终需要记录的值为 8Y+2Cr+2Cb = 12,而如果使用RGB来记录则会需要3x8=24。
YCbCr的优势就在于,在达到最大压缩率的情况下,能够保证对人眼感知的失真度最小。拿4:2:0来说足足压缩了一半。
YUV按照存储方式又可以分为下面两种
planar
YCbCr分别存储在不同的平面中。根据CbCr存储的顺序不同,又分为I420和YV12。
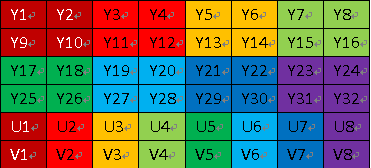
- I420 : 也叫YU12,先存储Y,再存Cb,最后存Cr,最终数据结果是 YYYY CbCb CrCr,也就是上图所展示的。
- YV12:先存储Y,再存Cr,最后存Cb,最终数据结果是 YYYY CrCr CbCb
semi planar
Y单独一个平面,CbCr共用一个平面。根据CbCr存储的顺序不同,又分为NV12和NV21。
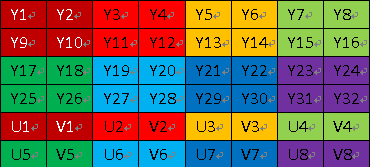
- NV12:先存储Y,然后CbCr交替存储,最终数据结果为 YYYY CbCr CbCr,也就是上图所展示的。(IOS中使用)
- NV21:先存储Y,然后CrCb交替存储,最终数据结果为 YYYY CrCb CrCb。(Android中使用)
视频的组成
前面说了这么多图像,现在我们来说说视频,所谓视频就像下面动图中展示的一样,视频是由连续的图像组成。视频的原理就是利用人眼的特殊结构,当画面在快速切换时,画面会有残留,所以人感觉起来就像是连贯的动作。

视频帧
帧是视频流的一个基本单位,可以将其联想成一幅静态图像,一个YCbCr格式的图像。
帧率
帧率指的是视频每秒包含的帧数(FPS,Frame per second),帧率是衡量视频质量的一个重要指标。
帧率越高,则视频会越流畅,一般视频都是24-30帧之间,电影一般都保持在24帧,而手机一般拍摄都默认在30帧,最高可以拍摄60帧的视频。
色彩位数
表示一个像素中存储颜色所用的位数,位数越高,则颜色越丰富。常见的有8位、16位、24位、32位,其中24位是最常用的,称为真彩,而32位是在24位上加了8位表示透明度。
场(扩展)
大家应该都听说过1080P,这是一种视频显示格式,那么大家有没有听过说1080I呢?
1080I指的是在电视信号中,采用隔行交错扫描视频的信号格式。而1080P指的是用逐行扫描视频的显示格式。
为什么会有隔行扫描呢?因为早期电视机没办法处理大量复杂的数据,没发观看高清电视,所以采用了隔行扫描,将每一帧图像,按照单行和双行分为两场,顶场和低场,两场交替显示。在PAL制式的电视台规定是每秒25帧,每帧两场,也就是每秒50场,所以PAL制式的扫描频率就是50HZ。
人类视觉系统HVS(扩展)
HVS由眼睛+神经+大脑组成。视频的一些设计就是根据HVS的特点来的。
- 对高频信息不敏感 -> 丢弃高频信息,只编码低频信息
- 对高对比度更敏感 -> 提高边缘信息的主观质量
- 对亮度信息比色度信息更敏感 -> 降低色度的解析度
- 对运动的信息更敏感 -> 对ROI区域进行特殊处理
什么是音频
上面讲了图像的数字化表现形式,那么声音如何数字化呢?
声音的产生
声音是由物体振动产生的,再通过空气、固体、液体等传输,传入人耳后振动耳膜,再通过听觉神经传递给大脑
声音的三要素
- 音调 :音频振动的快慢 (男生 < 女生 < 儿童)
- 音量 :振动的幅度
- 音色 :声波是由基波和谐波组合成,不同频谱的谐波比例不同,音色也就不同
人类听觉范围 = 次声波 ~ 20Hz ~ 20kHz ~ 超声波
PCM
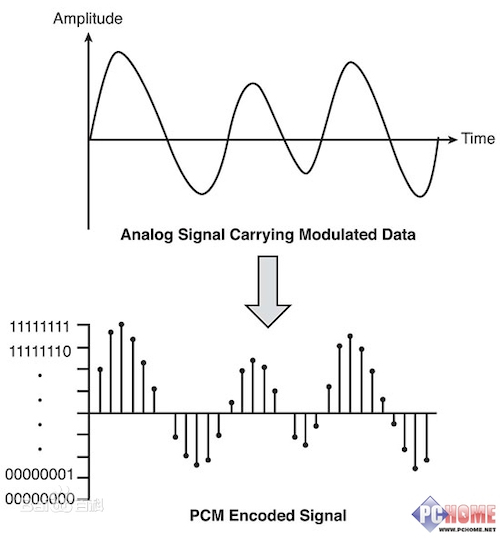
声音是一种波,是一种模拟信号,模拟信号是指时间上和数值上连续的信号。而模拟信号想要用于计算机,就必须将模拟信号转为数字信号。而PCM(脉冲编码调制)就是将输入的模拟信号进行采样、量化、编码,最终输出为数字信号。
模拟信号 -> 采样 -> 量化 -> 编码 -> 数字信号
采样
采样就是把时间连续的模拟信号变成时间离散、幅度连续的数字信号。
采样率
采样率就是指每秒采集的样本数,常见的有 8k、16k、32k、44.1k、48k等。
Nyquist采样定律:采样率大于或等于连续信号最高频率分量的2倍时,采样信号可以用来完美重构连续信号。而人类正常感知的频率在22.05kHz以下,所以最常见的采样率是44.1kHz,也就是每秒采样44100个采样点。
采样位数
就是采样值的范围,一般有8位、16位、32位。位数越多,音量起伏的大小变化就能够更精细的被记录下来,还原度越高。一般采用的都是16位,32位太扩张了。
声道
声音的通道的数目,指声音在录制和播放的时候在不同空间位置采集或回放的相互独立的音频信号,简单来说就是声音录制时的音频源数量或回放时相应的扬声器数量。分为单声道、双声道、多声道。其中双声道是使用最普遍的。
量化
采样后的信号虽然在时间上是离散的,但是其值的取值范围依旧是无限的,所以需要将无限的值量化到一定范围内的有限值。
编码
将量化后的采样值编码成二进制码流的过程称为编码。
为什么要编码
当一个音视频文件生产的时候,就面临了两个问题:
- 存储
- 传输
为什么存储和传输会是个问题呢?我们来计算下一个原始未压缩的视频会有多大,已一个1080x1920分辨率、帧率是30的90分钟视频为例
1 | 单帧大小 1920x1080 = 2073600个像素点,按照RGB来算就是 2073600x3byte = 6220800byte ≈ 5.9MB,按照YUV来计算就是 ≈ 2.9MB。 |
是不是很恐怖?一部电影居然就接近460GB了,想想当前的硬盘大小和网速,怎么可能存储和传输呢。
所以必须要对视频进行编码,编码就是按指定的方式,将信息从一种形式转换成另一种形式。编码的目的,就是为了压缩,各种视频编码方式,都是为了将视频变得更小,便于存储和传输。
视频编码
编码原理
压缩编码的核心思想就是去除冗余信息。常见的编码方式有预测编码和变换编码以及熵编码,其中预测编码是压缩率最大的一种。
预测编码
帧内预测编码
从空间角度出发,图像相邻像素之间有较强的相关性,可以从空间上去帧内像素之间的冗余。比如说下面这一帧,其中尘土的颜色、背景的颜色都是大致相同的,完全没有必要每个像素都记录一次颜色。

帧间预测编码
从时间角度出发,视频序列的相邻图像之间的内容有相似性,可以从时间上去除帧与帧之间的冗余。比如说下面这一个视频序列(假设这是一个2秒50帧的视频序列),我们可以发现这50帧里,除了结印的手在变动,其它地方都没有变化。那么其它未变的地方真的要存储50份一样的数据吗?是不是可以省略掉,存储一份就够了。

变换编码
大多数视频图像都和上面展示的一样,变动的区域只是一小部分,大部分区域是不变的,可就是说低频区占大部分,高频区占小部分。然后将空间域的图像变换到频率域,会产生相关性很小的变换系数,然后再对变换系数进行量化,利用上面人类视觉体统特点所说到的,人对高频信息不敏感的特征,对低频区的系数进行细量化,对高频区的系数进行粗量化,从而降低信息传递量,达到压缩的目的。
简单的解释变换,就是如下图所示,坐标系中有ABC三点,我们将坐标轴调整一下,ABC三点的坐标值就会变小。
![]()
一个8x8的像素区域,假设其像素颜色值如下图所示
![]()
像素区域经过DCT(离散余弦变换)变换后,生产的变换系数,如下图所示
![]()
对变换系数进行量化,量化后大部分都会变成0,此时只需要将这些非0的值进行编码即可,入下图所示
![]()
熵编码
利用信息的统计特性,使用新的编码来表示输入的数据,比如说哈夫曼编码、CABAC。简单解释就是给高频数据短码,给低频数据长码,比如 A 是高频数据,则编码为 01,G是低频数据,则编码为 01010001。
编码模型(扩展)
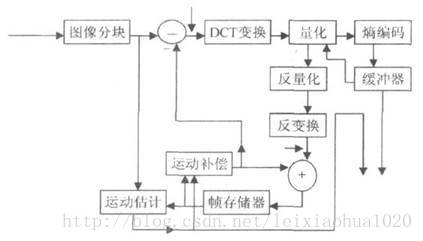
常见编码格式
常见的编码格式有H.26x系列和MPEG系列,其中H.26x系统是由ITU组织(国际电信联盟)主导,而MPEG系列由ISO(国际标准化组织)下的MPEG(动态图像专家组)组织主导的。
目前主流的H.264和H.265编码格式是由ITU和MPEG两个组织合力制定的。
H.264与MPEG-4 AVC的关系
在早期,ITU和MPEG两家组织都是各搞各的,ITU组织推行了H.261、H.262、H.263编码格式,而MPEG组织则推行了MPEG-1、MPEG-2、MPEG-3标准族群。后来两家组织准备合力制作新一代的视频编码标准,对于ITU组织来说,将这个新一代的编码标准命名为H.264,而对于MPEG来说,这个新一代的压缩标准只是其MPEG-4标准的第10部分,其第10部分叫做高级视频编码AVC(Advanced Video Coding)。
所以可以简单的认为H.264就是MPEG-4 AVC。
Annex B格式和AVCC格式(扩展)
- Annex B格式
这种格式的H.264码流用于实时流的传播中,其特点是码流中每个NALU(单元块)之间通过起始码来分割,起始码分为两种,一帧开始则用四个字节的1来表示,不是一帧开始就用三个字节的1来表示。
H.264原始码流是由一系列的NALU组成(Network Abstraction Layer Unit),不同的NALU数据量不同。
- AVCC格式
这种格式的H.264码流用于磁盘文件中(MP4等媒体文件),其特点是没有起始码,而是将起始码替换成了size,是为了应对存储文件的可随机访问特性。
H.265与MPEG-H HEVC
H.265和H.264一样,依旧是ITU和MPEG两家合力制定的。H.265被定义在MPEG-H的第2部分,称为高效率视频编码 High Efficiency Video Coding。
H.265的压缩率是H.264的两倍,并且支持4K清晰度,最高支持到8K。目前主流的设备基本都支持H.265编码。
音频编码
编码原理
音频编码是在保证信号在听觉方面不产生失真的前提下,对音频数据进行尽可能大的压缩。其原理是通过去除声音信号中冗余成分来实现,所谓冗余成分就是指不在人耳听觉范围内的音频信号以及被掩蔽掉的音频信号。
不在人耳听觉范围内的音频信号是因为人耳能够察觉的声音信号的频率范围为20Hz-20KHz,除此之外的频率是无法察觉的。
被掩蔽掉的音频信号是因为当一个强音信号与一个弱音信号同时存在时,弱音信号将被强音信号所掩蔽而听不见,所以此时弱音信号可以视为冗余而不用传输。
频谱掩蔽效应
相同音量下,频率低的被遮蔽;相同频率下,音量小的被遮蔽;
时域掩蔽效应
时间上相邻的声音之间也有掩蔽现象,分为超前掩蔽和滞后掩蔽。产生时域掩蔽的主要原因是人的大脑处理信息需要花费一定的时间,超前掩蔽很短,只有大约520ms,而滞后掩蔽可以持续50200ms。
编码模型(扩展)
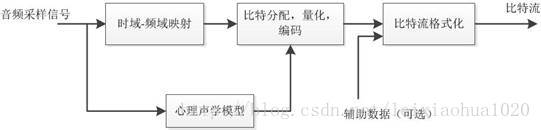
常见编码格式
如果说视频编码被H.264和H.265所统治,那么统治音频编码的就是AAC了。AAC全称是Advanced Audio Coding,是一个有损压缩的音频编码集。除了AAC编码外,Opus编码在即时通信领域上使用的比较广泛。
ACC规格
- AAC-LC
AAC-LC的全称是Advanced Audio Coding Low-Complexity,用于存储空间和计算能力有限的情况,这种类型没有使用预测和增益控制,瞬时噪声整形的阶数也比较低。
- AAC-LD
AAC-LD的全称是Advanced Audio Coding Low-Delay,是源于AAC-LC,结合了感知音频编码和双向通道的低延时要求,减小的算法的延时。
AAC-HE-V1
核心思想是按频谱保存,将时域转换为频域,将低频编码保存为主要部分,将高频单独放大编码保存。
AAC-HE-V2
核心思想是双声道中的声音存在某种相似性,只需存储一个声道的全部信息,然后花很少的字节用参数描述另一个声道和它不同的地方。
AAV格式
- ADIF格式
ADIF是在MPEG-2中定义的,其特点是可以确定的找到这个音频数据的开始,解码必须在明确定义的开始处进行,这种格式常用在磁盘文件中。
- ADTS格式
ADTS的特征是它有一个同步字的比特流,解码可以在这个流的任何位置开始,帧同步目的就是在于找出帧头在比特流中的位置,ADTS的同步字为三个字节的1111 1111 1111来表示。
- LATM格式
LATM是在MPEG-4中制定的一种高效率的码流传输方式。
为什么要封装?
所谓封装就是定义一个容器,将视频、音频、字幕等数据都混合封装在容器中。容器使得媒体内容的同步播放变得简单,另外容器中还会存储媒体内容的基本信息以及媒体内容的帧索引,方便快速拖动和跳转到指定位置。
常见封装格式
MPEG格式
后缀为(.mp4等),常用的一般是MPEG-4标准的第14部分定义的MP4文件格式。
QuickTime File Format格式
后缀为 .mov ,苹果公司推出的一种视频封装格式,常用于苹果设备。
Flash Video格式
后缀为 .flv,Adobe Flash延伸出来的一种视频封装格式。
硬解与软解的区别
硬解码
调用soc中的专门模块来进行编解码,减少了对CPU的占用,且更加省电,但是缺点是在Android手机上,由于国内产商使用的芯片参差不齐,会有很多兼容性的问题。
SOC芯片
手机SOC芯片,就是在一个芯片里面集成CPU、GPU、SP、ISP、RAM内存、WIFI控制器、基带芯片、音频芯片等。

Android平台MediaCodec
在Android平台的上,提供的编解码API就是MediaCodec,该API在21之前都只有Java层实现,在21后提供了C实现。MediaCodec与底层硬件的交互,是通过OpenMax来实现的。
IOS平台VideoToolBox
软解码
软解码是指通过CPU来对视频进行编解码处理,常用的开源库是FFmpeg,相对于硬解码来说,软解码的兼容性非常好,但是缺点也很明显,占用CPU,费电,在处理速度上会比硬解码慢。